The End of Tech Companies
“If you aren’t genuinely pained by the risk involved in your strategic choices, it’s not much of a strategy.” — Reed Hastings
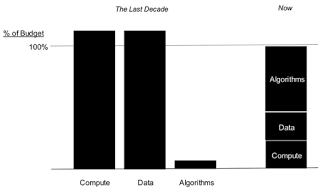
Enterprise software companies are facing unprecedented market pressure. With the emergence of cloud, digital, machine learning, and analytics (to name a few), the traditional business models, cash flows, and unit economics are under pressure. The results can be seen in some public stock prices (HDP, TDC, IMPV, etc.), and nearly everyone’s financials (flat to declining revenues in traditional spaces).
The results can also be seen in the number of private transactions occurring (Informatica, Qlik, etc.); it’s easier to change your business model outside of the public eye. In short, business models reliant on traditional distribution models, large dollar transactions, and human-intensive operations will remain under pressure.
Many ‘non-tech companies’ tell me, “thank goodness that is not the business we are in” or “technology changes too fast, I’m glad we are in a more traditional space”. These are false hopes. This fundamental shift is coming (or has already come) to every business and every industry, in every part of the world. It does not matter if you are a retailer, a manufacturer, a healthcare provider, an agricultural producer, or a pharma company. Your traditional distribution model, operational mechanics, and method of value creation will change in the next 5 years; you will either lead or be left behind.
It’s been said that we sit on the cusp of the next Industrial Revolution. Data, IoT, and software are replacing industrialization as the driving force of productivity and change. Look no further than the public markets; the 5 largest companies in the world by value are:

As Benedict Evans observed, “It is easier for software to enter other industries than for other industries to hire software people.” In the same vein, Naval Ravikant commented, “Competing without software is like competing without electricity.” The rise of the Data era, coupled with software and connected device sprawl, creates an opportunity for some companies to outperform others. Those who figure out how to apply this advantage will drive unprecedented wealth creation and comprise the new S&P 500.
This is the end of ‘tech companies’. The era of “tech companies” is over; there are only ‘companies’, steeped in technology, that will survive.
Read the rest on Medium here.
Enterprise software companies are facing unprecedented market pressure. With the emergence of cloud, digital, machine learning, and analytics (to name a few), the traditional business models, cash flows, and unit economics are under pressure. The results can be seen in some public stock prices (HDP, TDC, IMPV, etc.), and nearly everyone’s financials (flat to declining revenues in traditional spaces).
The results can also be seen in the number of private transactions occurring (Informatica, Qlik, etc.); it’s easier to change your business model outside of the public eye. In short, business models reliant on traditional distribution models, large dollar transactions, and human-intensive operations will remain under pressure.
Many ‘non-tech companies’ tell me, “thank goodness that is not the business we are in” or “technology changes too fast, I’m glad we are in a more traditional space”. These are false hopes. This fundamental shift is coming (or has already come) to every business and every industry, in every part of the world. It does not matter if you are a retailer, a manufacturer, a healthcare provider, an agricultural producer, or a pharma company. Your traditional distribution model, operational mechanics, and method of value creation will change in the next 5 years; you will either lead or be left behind.
It’s been said that we sit on the cusp of the next Industrial Revolution. Data, IoT, and software are replacing industrialization as the driving force of productivity and change. Look no further than the public markets; the 5 largest companies in the world by value are:
As Benedict Evans observed, “It is easier for software to enter other industries than for other industries to hire software people.” In the same vein, Naval Ravikant commented, “Competing without software is like competing without electricity.” The rise of the Data era, coupled with software and connected device sprawl, creates an opportunity for some companies to outperform others. Those who figure out how to apply this advantage will drive unprecedented wealth creation and comprise the new S&P 500.
This is the end of ‘tech companies’. The era of “tech companies” is over; there are only ‘companies’, steeped in technology, that will survive.
Read the rest on Medium here.